February 8, 2022
Data Visualization: Creating Impactful Reports
Data visualization is a great way to create impactful reports, dashboards that improve decision making, better ad-hoc data…

Whether you require new development, enhancements or support, DataFactZ simply becomes your extended analytics workforce.
Our experts can help assess and analyze your organization’s BI needs and recommend an appropriate solution that makes the most business sense, still balancing cost and delivering ROI for your BI investment. DataFactZ’s BI development capabilities cover the complete spectrum, including data integration, analysis, reporting and analytical applications. We have a depth of knowledge and experience to design, develop, and implement BI projects right, gathering requirements for current or future business objectives.
Experience working on more than 1000+ BI/EDW development projects across various industries.
150+ application migrations from one technology to another.
On-site, onshore and offshore development model with offices in Northville, MI and Hyderabad, India.
We thrive on being able to help companies surface the smallest of details without missing the big picture. Our experts create data and analytics solutions with scalability always in mind, striving to deliver maximum insightful information to our clients.
DataFactZ is a technology partner with all major Business Intelligence Software providers.
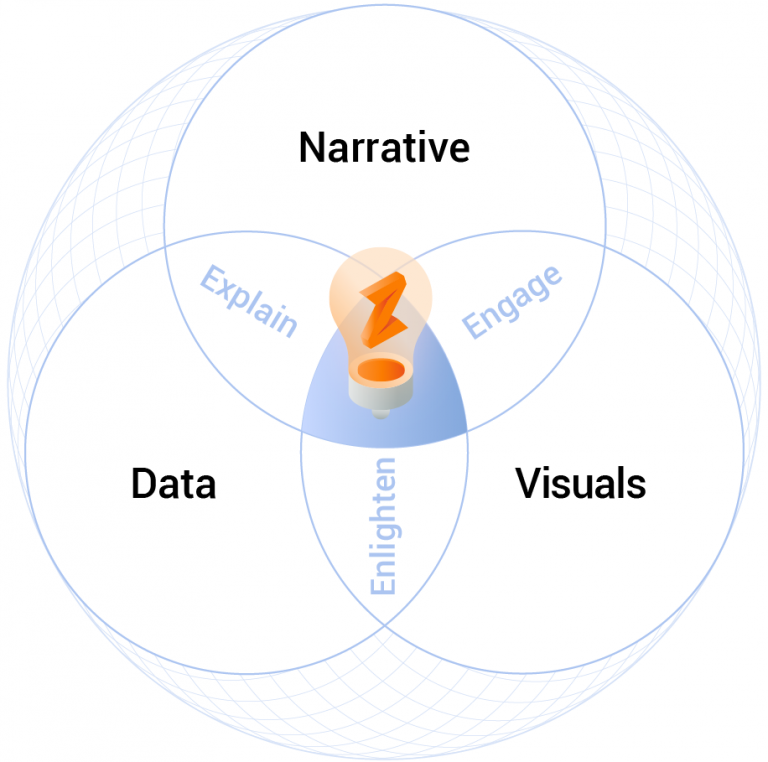
More than graphs and charts, more than tech considerations, defining the question to be answered and the narrative that will effectively connect, inform, and build trust is key to any data visualization challenge. Many companies will recognize that becoming “data-driven” requires skilled developers and analysts, but without bridging the gap between data and consumption, execution falls short.
Data story-telling has become even more crucial with the advent of self-service BI, combining explorative data visualization with narrative techniques to deliver insights in a compelling form.
From concept and mock-ups to delivery, our focus is personalized usability—intuitive interfaces that are actionable by the end user to maximize adoption and ROI.
Our data science solutions enable your organization to become truly data-driven.
With successful executions across various domains including financial services, retail and health care, our associates are equipped to join industry best practices with your organization’s potential.
Data-led Transformation helps you create operational efficiencies to support growth, create sustainability for long-term requirements, and differentiate your organization with new technologies that will continuously meet your business needs.
DataFactZ helps you create a data-driven migration plan that harnesses AI, and intelligent data to create a cross-functional data platform that connects your business through the cloud providing a single source of accurate data and business insights. We are here to support your transition!
DataFactZ offers meaningful analytics and insights for the following types of businesses: Healthcare, Finances, Customer, Manufacturing, Assets, Supply Chain, Transportation & Logistics. HR, Sales & Products, and many more.
DataFactZ has experience in the following types of services: Analytics as a Service (AaaS), Managed Data Analysis, Data Analytics consulting, Data Analytics Implementation, Data Analytics Modernization and Data Management Services.
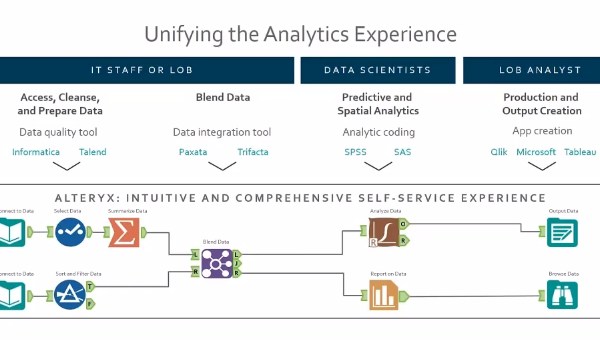
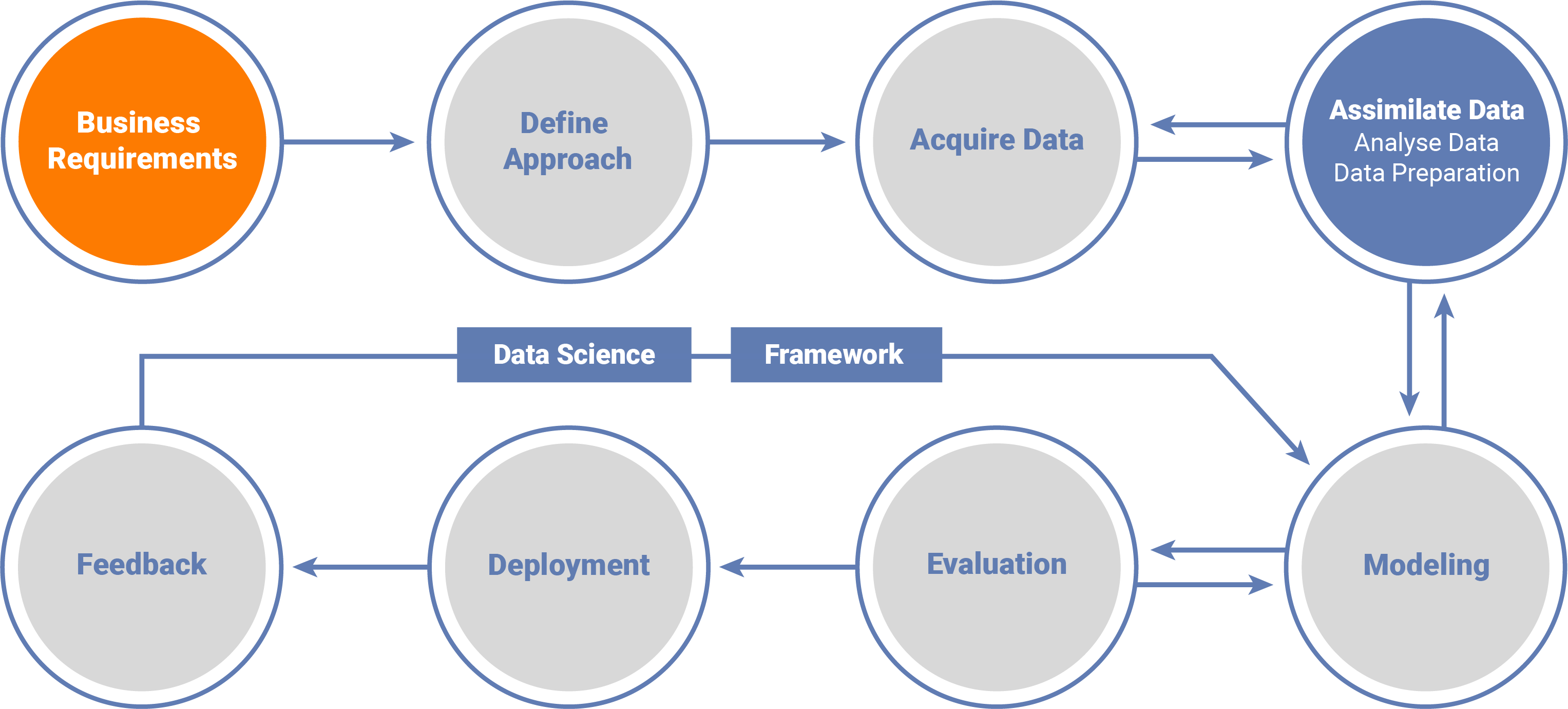
The main types of Data Analytics Solutions are: Data Integration and Data Warehousing, Self-Service BI, Data Visualization, Data Science and Big Data. DataFactZ has experience in all these types of solutions and we’re ready to help you implement them!
Business analytics is a broad term that can differ from industry to industry. Data analytics are often used to improve financial stability, forecast demand, increase productivity, create marketing strategies, increase sales and data visualization.
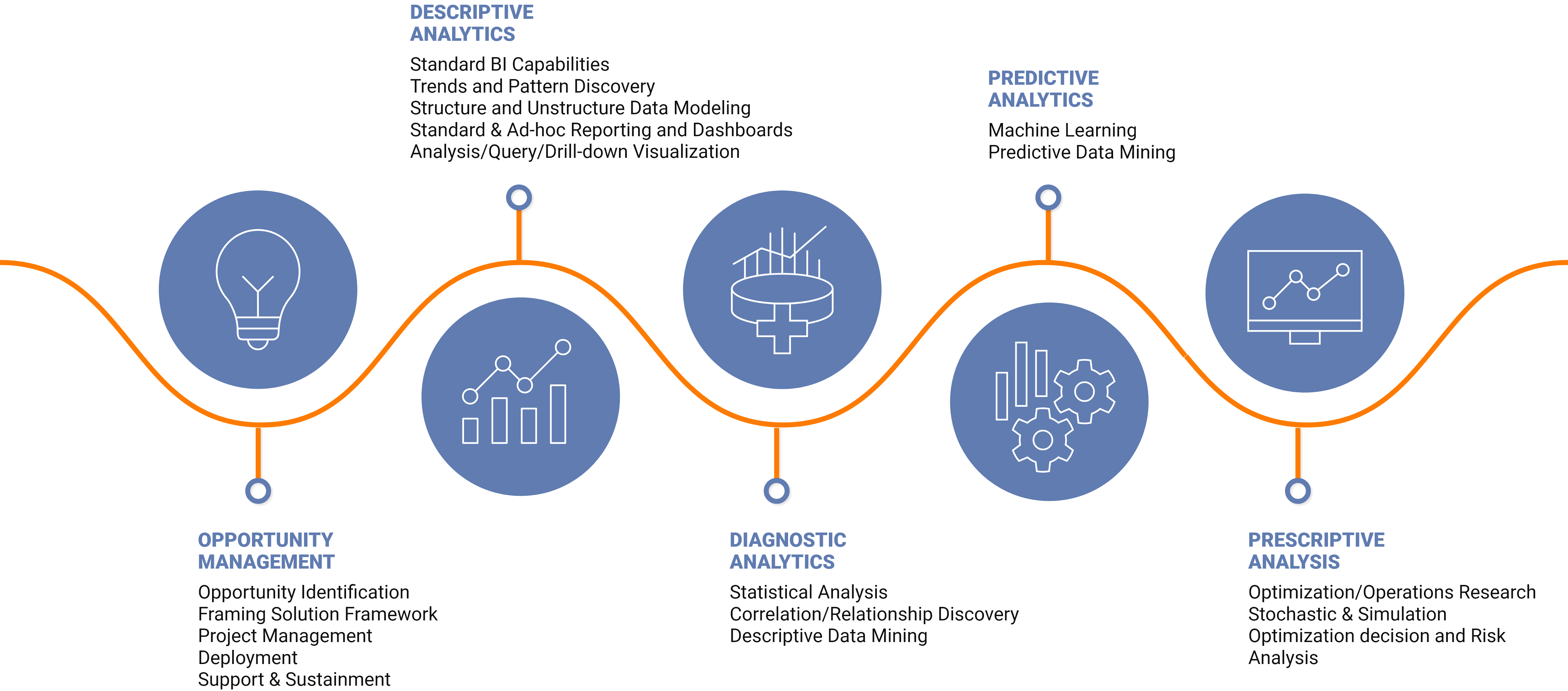
The Four types of business analytics are:
Data analytics is multifaceted in its business use. Data can be leveraged to detect anomalies, negate risk, manage customer data, research, detect fraud, and analyze operations.
Predictive analytics is a way that businesses use data to analyze the likelihood of certain outcomes. This is done through the use of historical data, current data, statistics and machine learning. There are many business functions for predictive analysis including fraud detection, manufacturing, pricing and customer relationship management.
Prescriptive analysis can only be done when a problem that needs solving has been identified. Once a problem has been identified an algorithm will use data to identify where the problem is occurring from so your company can make a decision on how to proceed. The accuracy of the recommendation will be based on having good data and can be customized to specific situations.