If you’ve been around the technology block for a while, chances are, the term ‘Big Data’ is not unfamiliar to you. It has been thrown around so much that even making fun of its over usage is clichéd. I remember a conversation with a client who expressed a whole lot of interest to move their existing systems to Big Data, and believed it is somehow the right thing to do. The overall data their department owned, summed up to less than 100 GB, and this included historical data.
Big data at its crux, is distributed computing. Distributed computing is justified if you have large amounts of data to store, process and analyze. Assuming you have reasoned the immediate use of big data at your company, understanding the different areas where distributed computing is relevant, is important.
After years of experience working on projects related to data, I have learned that problems involving data analysis can be broadly classified into five distinct areas. This classification, as shown below, is based on how the end users want to view the data.
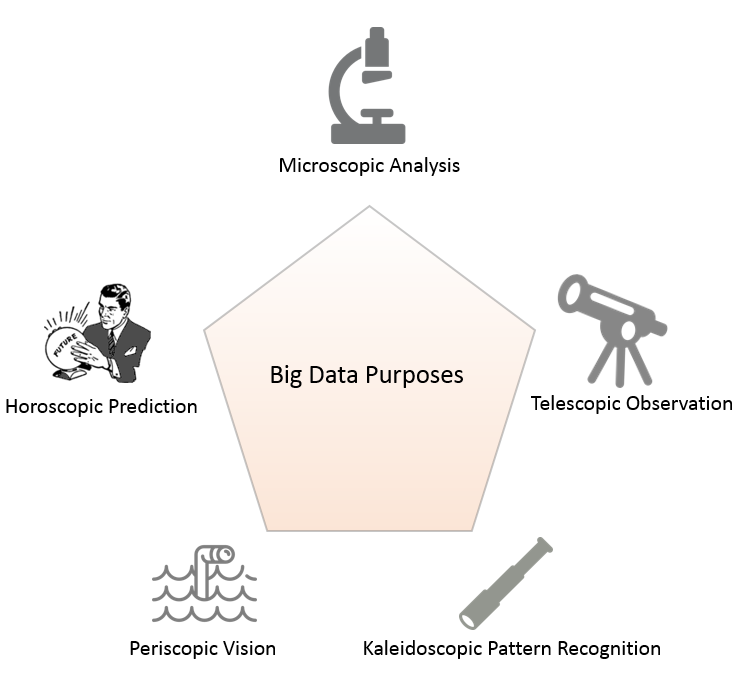
Microscopic Analysis
Some of the repeating requests IT gets from data analysts is around entity specific information. For example, revenue generated by a particular customer, dollar transaction with a particular vendor, or cost of a given product. Data Engineers write one-off queries to retrieve this information, as these requests are usually expected to be resolved sooner than later.
In most cases you don’t need a big data solution for these problems. However, if you have extremely extremely large data sets, and the requested information needs complex computing, and time is not a luxury, big data solutions that use in-memory computing to solve problems can be your answer.
A great platform to get you start playing on this is Apache Spark. With its rich libraries, and ability to do real time computing, this technology can prove to be extremely useful.
Telescopic Observations
This is by far the most common request IT gets. ‘C’ level execs love to view data from a distance. This gives them the ‘big picture’ and help them with informed decision making. Sales by Region, Costs by Department, Revenue by Market, the list goes on. The solution to most of these requests involve crunching millions and even billions of rows of data.
This is where a big data solution flies, and it flies high. This may be your justification to use big data especially if the data is large, unstructured and requires columnar storage.
Apache Cassandra is one of the more popular big data storage solutions. With its emphasis on easy scalability, high availability and eventual consistency, the increasing popularity of this technology is evident.
Periscopic Vision
Not all questions can be answered by the data you own. In traditional database systems, reporting and business intelligence solutions are limited to the data that you have at your disposal. With companies embracing technology more than ever before, insights prove to be a useful weapon in the world of cut-throat competition. Getting insights from data that is beyond your direct line of sight can give you the edge that you always wanted.
This is where combining proprietary in-house data with external data sources can bring value to a business. An example is deriving the relationship between a company’s sales to weather, in real time. For a use case such as this, Apache Flume and Apache Kafka provide unparalleled data stream ingestion and messaging services respectively.
Without a good storage plan, volume eventually becomes a concern with data streaming solutions. Apache Cassandra could be your savior in this case as well.
Kaleidoscopic Pattern recognition
This may be the one technological concept in the big data world that has the highest impact on ROI. As kids, we desired kaleidoscopes because they were fun. Viewing the changing patterns through a pipe made with glass walls were a thing of wonder. To many businesses, pattern recognition is still a thing of wonder as they use it to identify surprising trends that are not obvious. This is mainly due to the fact that traditional business intelligence tools are not suited best for this purpose. One, they can’t handle large data sets as well as big data technologies. Two, they just don’t have advanced pattern recognition capabilities.
This section of the big data spectrum comprises of text mining, social network analysis, sentiment analysis and deep learning to name a few. The idea is to make computing systems give us information that is not apparent otherwise. Its applications range from Speech and Image recognition to Natural Language Processing. If you are working on Artificial Intelligence products, this can be an exciting area for you.
If you are interested in applying these techniques to solve your business problem, a good place to start would be delving into products such as Apache Mahout and DL4J.
Horoscopic Prediction
Okay, I admit I could have used just the word ‘prediction’ for this classification, but where is the fun in that? On a serious note, this advanced area of the big data space is much sought after by businesses for various reasons. Horoscope, in the traditional sense, is a means to predict the future. Predicting and forecasting helps companies to plan their resources appropriately and target the right demographics at the right time to make and save money.
Fraud detection, customer behavior prediction, research etc. are some of the areas this is prevalent. Machine learning and Graph computation libraries can come to your aid if this is your focus area.
As businesses continue to engage in advanced technologies such as these, quality and consistency of data needs to be in check too. “Timeliness and accuracy are most important as these determine whether or not your predictions are going to be of any use in practice”, says Dr. Satyendra Rana, CTO of Loven Systems.
Transition to new tools, technology and environment can be a daunting experience. Dr. Rana adds, “Expertise for making judicious choice of methods, platforms, and problem formulation only comes from experience and multi-disciplinary knowledge.” However, this should not discourage you from venturing into this area. If you have the right use case for a big data solution, it’s about time you start playing with it!
Amar Meda
Principal Solutions Architect, DataFactZ
Credit for images: www.freepik.com